Spark Interview Questions for Intermediates
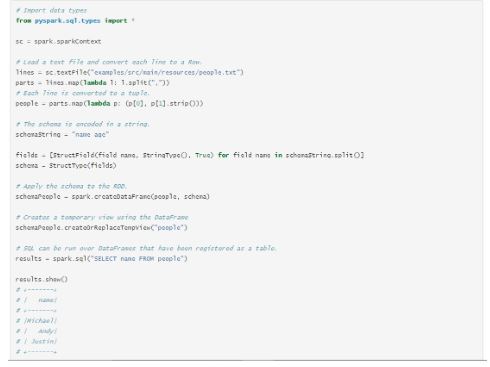
1. How to programmatically specify a schema for DataFrame?
DataFrame can be created programmatically with three steps:
- Create an RDD of Rows from the original RDD;
- Create the schema represented by a StructType matching the structure of Rows in the RDD created in Step 1.
- Apply the schema to the RDD of Rows via createDataFrame method provided by SparkSession.
2. Which transformation returns a new DStream by selecting only those records of the source DStream for which the function returns true?
1. map(func)
2. transform(func)
3. filter(func)
4. count()
The correct answer is c) filter(func).
3. Does Apache Spark provide checkpoints?
Yes, Apache Spark provides an API for adding and managing checkpoints. Checkpointing is the process of making streaming applications resilient to failures. It allows you to save the data and metadata into a checkpointing directory. In case of a failure, the spark can recover this data and start from wherever it has stopped.
There are 2 types of data for which we can use checkpointing in Spark.
Metadata Checkpointing: Metadata means the data about data. It refers to saving the metadata to fault-tolerant storage like HDFS. Metadata includes configurations, DStream operations, and incomplete batches.
Data Checkpointing: Here, we save the RDD to reliable storage because its need arises in some of the stateful transformations. In this case, the upcoming RDD depends on the RDDs of previous batches.
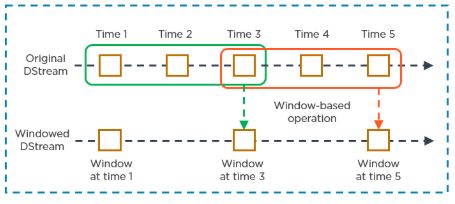
4. What do you mean by sliding window operation?
Controlling the transmission of data packets between multiple computer networks is done by the sliding window. Spark Streaming library provides windowed computations where the transformations on RDDs are applied over a sliding window of data.
5. What are the different levels of persistence in Spark?
DISK_ONLY – Stores the RDD partitions only on the disk
MEMORY_ONLY_SER – Stores the RDD as serialized Java objects with a one-byte array per partition
MEMORY_ONLY – Stores the RDD as deserialized Java objects in the JVM. If the RDD is not able to fit in the memory available, some partitions won’t be cached
OFF_HEAP – Works like MEMORY_ONLY_SER but stores the data in off-heap memory
MEMORY_AND_DISK – Stores RDD as deserialized Java objects in the JVM. In case the RDD is not able to fit in the memory, additional partitions are stored on the disk
MEMORY_AND_DISK_SER – Identical to MEMORY_ONLY_SER with the exception of storing partitions not able to fit in the memory to the disk
6. What is the difference between map and flatMap transformation in Spark Streaming?
| map() | flatMap() |
| A map function returns a new DStream by passing each element of the source DStream through a function func | It is similar to the map function and applies to each element of RDD and it returns the result as a new RDD |
| Spark Map function takes one element as an input process it according to custom code (specified by the developer) and returns one element at a time | FlatMap allows returning 0, 1, or more elements from the map function. In the FlatMap operation |
7. How would you compute the total count of unique words in Spark?
1. Load the text file as RDD:
sc.textFile(“hdfs://Hadoop/user/test_file.txt”);
2. Function that breaks each line into words:
def toWords(line):
return line.split();
3. Run the toWords function on each element of RDD in Spark as flatMap transformation:
words = line.flatMap(toWords);
4. Convert each word into (key,value) pair:
def toTuple(word):
return (word, 1);
wordTuple = words.map(toTuple);
5. Perform reduceByKey() action:
def sum(x, y):
return x+y:
counts = wordsTuple.reduceByKey(sum)
6. Print:
counts.collect()
8. Suppose you have a huge text file. How will you check if a particular keyword exists using Spark?
lines = sc.textFile(“hdfs://Hadoop/user/test_file.txt”);
def isFound(line):
if line.find(“my_keyword”) > -1
return 1
return 0
foundBits = lines.map(isFound);
sum = foundBits.reduce(sum);
if sum > 0:
print “Found”
else:
print “Not Found”;
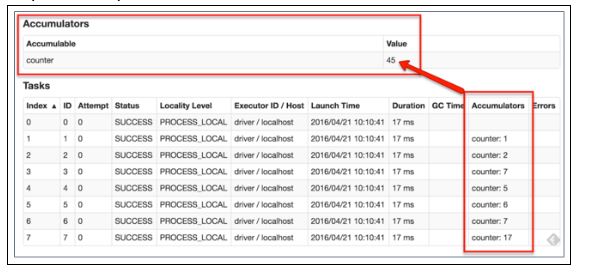
9. What is the role of accumulators in Spark?
Accumulators are variables used for aggregating information across the executors. This information can be about the data or API diagnosis like how many records are corrupted or how many times a library API was called.
10. What are the different MLlib tools available in Spark?
- ML Algorithms: Classification, Regression, Clustering, and Collaborative filtering
- Featurization: Feature extraction, Transformation, Dimensionality reduction,
and Selection
- Pipelines: Tools for constructing, evaluating, and tuning ML pipelines
- Persistence: Saving and loading algorithms, models, and pipelines
- Utilities: Linear algebra, statistics, data handling
11. What are the different data types supported by Spark MLlib?
Spark MLlib supports local vectors and matrices stored on a single machine, as well as distributed matrices.
Local Vector: MLlib supports two types of local vectors – dense and sparse
Example: vector(1.0, 0.0, 3.0)
dense format: [1.0, 0.0, 3.0]
sparse format: (3, [0, 2]. [1.0, 3.0])
Labeled point: A labeled point is a local vector, either dense or sparse that is associated with a label/response.
Example: In binary classification, a label should be either 0 (negative) or 1 (positive)
Local Matrix: A local matrix has integer type row and column indices, and double type values that are stored in a single machine.

Distributed Matrix: A distributed matrix has long-type row and column indices and double-type values, and is stored in a distributed manner in one or more RDDs.
Types of the distributed matrix:
- RowMatrix
- IndexedRowMatrix
- CoordinatedMatrix
12. What is a Sparse Vector?
A Sparse vector is a type of local vector which is represented by an index array and a value array.
public class SparseVector
extends Object
implements Vector
Example: sparse1 = SparseVector(4, [1, 3], [3.0, 4.0])
where:
4 is the size of the vector
[1,3] are the ordered indices of the vector
[3,4] are the value
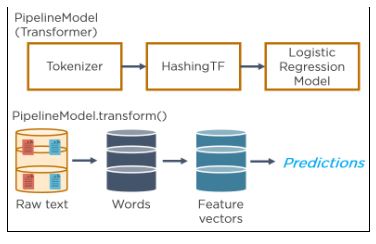
13. Describe how model creation works with MLlib and how the model is applied.
MLlib has 2 components:
Transformer: A transformer reads a DataFrame and returns a new DataFrame with a specific transformation applied.
Estimator: An estimator is a machine learning algorithm that takes a DataFrame to train a model and returns the model as a transformer.
Spark MLlib lets you combine multiple transformations into a pipeline to apply complex data transformations.
The following image shows such a pipeline for training a model:
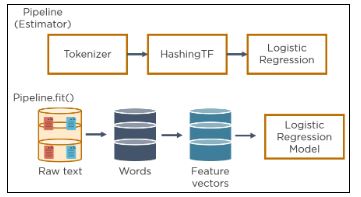
The model produced can then be applied to live data:
14. What are the functions of Spark SQL?
Spark SQL is Apache Spark’s module for working with structured data.
Spark SQL loads the data from a variety of structured data sources.
It queries data using SQL statements, both inside a Spark program and from external tools that connect to Spark SQL through standard database connectors (JDBC/ODBC).
It provides a rich integration between SQL and regular Python/Java/Scala code, including the ability to join RDDs and SQL tables and expose custom functions in SQL.
15. How can you connect Hive to Spark SQL?
To connect Hive to Spark SQL, place the hive-site.xml file in the conf directory of Spark.
Using the Spark Session object, you can construct a DataFrame.
result=spark.sql(“select * from <hive_table>”)
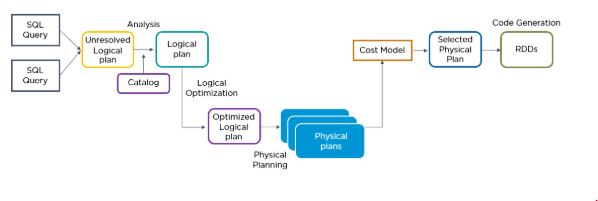
16. What is the role of Catalyst Optimizer in Spark SQL?
Catalyst optimizer leverages advanced programming language features (such as Scala’s pattern matching and quasi quotes) in a novel way to build an extensible query optimizer.
17. How can you manipulate structured data using domain-specific language in Spark SQL?
Structured data can be manipulated using domain-Specific language as follows:
Suppose there is a DataFrame with the following information:
val df = spark.read.json(“examples/src/main/resources/people.json”)
// Displays the content of the DataFrame to stdout
df.show()
// +—-+——-+
// | age| name|
// +—-+——-+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +—-+——-+
// Select only the “name” column
df.select(“name”).show()
// +——-+
// | name|
// +——-+
// |Michael|
// | Andy|
// | Justin|
// +——-+
// Select everybody, but increment the age by 1
df.select($”name”, $”age” + 1).show()
// +——-+———+
// | name|(age + 1)|
// +——-+———+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +——-+———+
// Select people older than 21
df.filter($”age” > 21).show()
// +—+—-+
// |age|name|
// +—+—-+
// | 30|Andy|
// +—+—-+
// Count people by age
df.groupBy(“age”).count().show()
// +—-+—–+
// | age|count|
// +—-+—–+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +—-+—–+
18. What are the different types of operators provided by the Apache GraphX library?
Property Operator: Property operators modify the vertex or edge properties using a user-defined map function and produce a new graph.
Structural Operator: Structure operators operate on the structure of an input graph and produce a new graph.
Join Operator: Join operators add data to graphs and generate new graphs.
19. What are the analytic algorithms provided in Apache Spark GraphX?
GraphX is Apache Spark’s API for graphs and graph-parallel computation. GraphX includes a set of graph algorithms to simplify analytics tasks. The algorithms are contained in the org.apache.spark.graphx.lib package and can be accessed directly as methods on Graph via GraphOps.
PageRank: PageRank is a graph parallel computation that measures the importance of each vertex in a graph. Example: You can run PageRank to evaluate what the most important pages in Wikipedia are.
Connected Components: The connected components algorithm labels each connected component of the graph with the ID of its lowest-numbered vertex. For example, in a social network, connected components can approximate clusters.
Triangle Counting: A vertex is part of a triangle when it has two adjacent vertices with an edge between them. GraphX implements a triangle counting algorithm in the TriangleCount object that determines the number of triangles passing through each vertex, providing a measure of clustering.
20. What is the PageRank algorithm in Apache Spark GraphX?
PageRank measures the importance of each vertex in a graph, assuming an edge from u to v represents an endorsement of v’s importance by u.

If a Twitter user is followed by many other users, that handle will be ranked high.

PageRank algorithm was originally developed by Larry Page and Sergey Brin to rank websites for Google. It can be applied to measure the influence of vertices in any network graph. PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The assumption is that more important websites are likely to receive more links from other websites.
A typical example of using Scala’s functional programming with Apache Spark RDDs to iteratively compute Page Ranks is shown below:


