Spark Interview Questions for Beginners
1. How is Apache Spark different from MapReduce?
| Apache Spark | MapReduce |
| Spark processes data in batches as well as in real-time | MapReduce processes data in batches only |
| Spark runs almost 100 times faster than Hadoop MapReduce | Hadoop MapReduce is slower when it comes to large scale data processing |
| Spark stores data in the RAM i.e. in-memory. So, it is easier to retrieve it | Hadoop MapReduce data is stored in HDFS and hence takes a long time to retrieve the data |
| Spark provides caching and in-memory data storage | Hadoop is highly disk-dependent |
2. What are the important components of the Spark ecosystem?
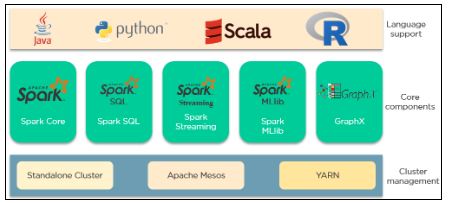
Apache Spark has 3 main categories that comprise its ecosystem. Those are:
- Language support: Spark can integrate with different languages to applications and perform analytics. These languages are Java, Python, Scala, and R.
- Core Components: Spark supports 5 main core components. There are Spark Core, Spark SQL, Spark Streaming, Spark MLlib, and GraphX.
- Cluster Management: Spark can be run in 3 environments. Those are the Standalone cluster, Apache Mesos, and YARN.
3. Explain how Spark runs applications with the help of its architecture.
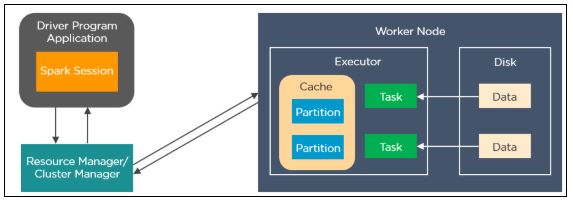
Spark applications run as independent processes that are coordinated by the SparkSession object in the driver program. The resource manager or cluster manager assigns tasks to the worker nodes with one task per partition. Iterative algorithms apply operations repeatedly to the data so they can benefit from caching datasets across iterations. A task applies its unit of work to the dataset in its partition and outputs a new partition dataset. Finally, the results are sent back to the driver application or can be saved to the disk.
4. What are the different cluster managers available in Apache Spark?
- Standalone Mode: By default, applications submitted to the standalone mode cluster will run in FIFO order, and each application will try to use all available nodes. You can launch a standalone cluster either manually, by starting a master and workers by hand, or use our provided launch scripts. It is also possible to run these daemons on a single machine for testing.
- Apache Mesos: Apache Mesos is an open-source project to manage computer clusters, and can also run Hadoop applications. The advantages of deploying Spark with Mesos include dynamic partitioning between Spark and other frameworks as well as scalable partitioning between multiple instances of Spark.
- Hadoop YARN: Apache YARN is the cluster resource manager of Hadoop 2. Spark can be run on YARN as well.
- Kubernetes: Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications.
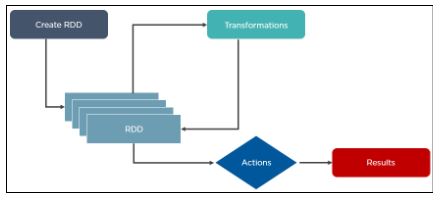
5. What is the significance of Resilient Distributed Datasets in Spark?
Resilient Distributed Datasets are the fundamental data structure of Apache Spark. It is embedded in Spark Core. RDDs are immutable, fault-tolerant, distributed collections of objects that can be operated on in parallel.RDD’s are split into partitions and can be executed on different nodes of a cluster.
RDDs are created by either transformation of existing RDDs or by loading an external dataset from stable storage like HDFS or HBase.
Here is how the architecture of RDD looks like:
6. What is a lazy evaluation in Spark?
When Spark operates on any dataset, it remembers the instructions. When a transformation such as a map() is called on an RDD, the operation is not performed instantly. Transformations in Spark are not evaluated until you perform an action, which aids in optimizing the overall data processing workflow, known as lazy evaluation.
7. What makes Spark good at low latency workloads like graph processing and Machine Learning?
Apache Spark stores data in-memory for faster processing and building machine learning models. Machine Learning algorithms require multiple iterations and different conceptual steps to create an optimal model. Graph algorithms traverse through all the nodes and edges to generate a graph. These low latency workloads that need multiple iterations can lead to increased performance.
8. How can you trigger automatic clean-ups in Spark to handle accumulated metadata?
To trigger the clean-ups, you need to set the parameter spark.cleaner.ttlx.
9. How can you connect Spark to Apache Mesos?
There are a total of 4 steps that can help you connect Spark to Apache Mesos.
- Configure the Spark Driver program to connect with Apache Mesos
- Put the Spark binary package in a location accessible by Mesos
- Install Spark in the same location as that of the Apache Mesos
- Configure the spark.mesos.executor.home property for pointing to the location where Spark is installed
10. What is a Parquet file and what are its advantages?
Parquet is a columnar format that is supported by several data processing systems. With the Parquet file, Spark can perform both read and write operations.
Some of the advantages of having a Parquet file are:
- It enables you to fetch specific columns for access.
- It consumes less space
- It follows the type-specific encoding
- It supports limited I/O operations
11. What is shuffling in Spark? When does it occur?
Shuffling is the process of redistributing data across partitions that may lead to data movement across the executors. The shuffle operation is implemented differently in Spark compared to Hadoop.
Shuffling has 2 important compression parameters:
spark.shuffle.compress – checks whether the engine would compress shuffle outputs or not spark.shuffle.spill.compress – decides whether to compress intermediate shuffle spill files or not
It occurs while joining two tables or while performing byKey operations such as GroupByKey or ReduceByKey
12. What is the use of coalesce in Spark?
Spark uses a coalesce method to reduce the number of partitions in a DataFrame.
Suppose you want to read data from a CSV file into an RDD having four partitions.

This is how a filter operation is performed to remove all the multiple of 10 from the data.
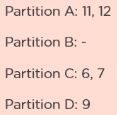
The RDD has some empty partitions. It makes sense to reduce the number of partitions, which can be achieved by using coalesce.

This is how the resultant RDD would look like after applying to coalesce.
13. How can you calculate the executor memory?
Consider the following cluster information:

Here is the number of core identification:

To calculate the number of executor identification:
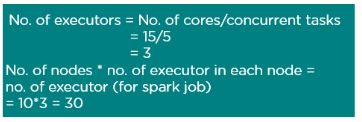
14. What are the various functionalities supported by Spark Core?
Spark Core is the engine for parallel and distributed processing of large data sets. The various functionalities supported by Spark Core include:
- Scheduling and monitoring jobs
- Memory management
- Fault recovery
- Task dispatching
15. How do you convert a Spark RDD into a DataFrame?
There are 2 ways to convert a Spark RDD into a DataFrame:
- Using the helper function – toDF
import com.mapr.db.spark.sql._
val df = sc.loadFromMapRDB(<table-name>)
.where(field(“first_name”) === “Peter”)
.select(“_id”, “first_name”).toDF()
- Using SparkSession.createDataFrame
You can convert an RDD[Row] to a DataFrame by
calling createDataFrame on a SparkSession object
def createDataFrame(RDD, schema:StructType)
16. Explain the types of operations supported by RDDs.
RDDs support 2 types of operation:
Transformations: Transformations are operations that are performed on an RDD to create a new RDD containing the results (Example: map, filter, join, union)
Actions: Actions are operations that return a value after running a computation on an RDD (Example: reduce, first, count)
17. What is a Lineage Graph?
A Lineage Graph is a dependencies graph between the existing RDD and the new RDD. It means that all the dependencies between the RDD will be recorded in a graph, rather than the original data.
The need for an RDD lineage graph happens when we want to compute a new RDD or if we want to recover the lost data from the lost persisted RDD. Spark does not support data replication in memory. So, if any data is lost, it can be rebuilt using RDD lineage. It is also called an RDD operator graph or RDD dependency graph.
18. What do you understand about DStreams in Spark?
Discretized Streams is the basic abstraction provided by Spark Streaming.
It represents a continuous stream of data that is either in the form of an input source or processed data stream generated by transforming the input stream.

19. Explain Caching in Spark Streaming.
Caching also known as Persistence is an optimization technique for Spark computations. Similar to RDDs, DStreams also allow developers to persist the stream’s data in memory. That is, using the persist() method on a DStream will automatically persist every RDD of that DStream in memory. It helps to save interim partial results so they can be reused in subsequent stages.
The default persistence level is set to replicate the data to two nodes for fault-tolerance, and for input streams that receive data over the network.

20. What is the need for broadcast variables in Spark?
Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used to give every node a copy of a large input dataset in an efficient manner. Spark distributes broadcast variables using efficient broadcast algorithms to reduce communication costs.
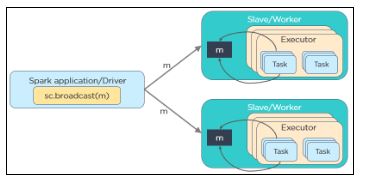
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)
Q7) What is Lazy evaluated?
Ans: If you execute a bunch of programs, it’s not mandatory to evaluate immediately. Especially in Transformations, this Laziness is a trigger.
Q8) What is Catchable?
Ans: Keep all the data in-memory for computation, rather than going to the disk. So Spark can catch the data 100 times faster than Hadoop.
Q9) What is Spark engine responsibility?
Ans: Spark responsible for scheduling, distributing, and monitoring the application across the cluster.
Q10) What are common Spark Ecosystems?
- Spark SQL(Shark) for SQL developers,
- Spark Streaming for streaming data,
- MLLib for machine learning algorithms,
- GraphX for Graph computation,
- SparkR to run R on Spark engine,
- BlinkDB enabling interactive queries over massive data are common Spark ecosystems. GraphX, SparkR, and BlinkDB are in the incubation stage.
Q11) What is Partitions?
Ans: Partition is a logical division of the data, this idea derived from Map-reduce (split). Logical data specifically derived to process the data. Small chunks of data also it can support scalability and speed up the process. Input data, intermediate data, and output data everything is Partitioned RDD.
Q12) How spark partition the data?
Ans: Spark use map-reduce API to do the partition the data. In Input format we can create number of partitions. By default HDFS block size is partition size (for best performance), but its’ possible to change partition size like Split.
Q13) How Spark store the data?
Ans: Spark is a processing engine, there is no storage engine. It can retrieve data from any storage engine like HDFS, S3 and other data resources.
Q14) Is it mandatory to start Hadoop to run spark application?
Ans: No not mandatory, but there is no separate storage in Spark, so it use local file system to store the data. You can load data from local system and process it, Hadoop or HDFS is not mandatory to run spark application.
Q15) What is SparkContext?
Ans: When a programmer creates a RDDs, SparkContext connect to the Spark cluster to create a new SparkContext object. SparkContext tell spark how to access the cluster. SparkConf is key factor to create programmer application.
Q16) What is SparkCore functionalities?
Ans: SparkCore is a base engine of apache spark framework. Memory management, fault tolarance, scheduling and monitoring jobs, interacting with store systems are primary functionalities of Spark.
Q17) How SparkSQL is different from HQL and SQL?
Ans: SparkSQL is a special component on the sparkCore engine that support SQL and HiveQueryLanguage without changing any syntax. It’s possible to join SQL table and HQL table.
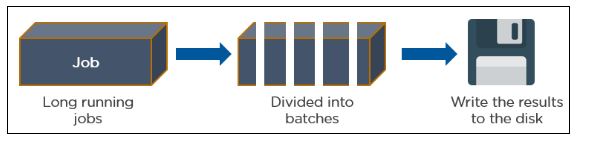
Q18) When did we use Spark Streaming?
Ans: Spark Streaming is a real time processing of streaming data API. Spark streaming gather streaming data from different resources like web server log files, social media data, stock market data or Hadoop ecosystems like Flume, and Kafka.
Q19) How Spark Streaming API works?
Ans: Programmer set a specific time in the configuration, within this time how much data gets into the Spark, that data separates as a batch. The input stream (DStream) goes into spark streaming. Framework breaks up into small chunks called batches, then feeds into the spark engine for processing. Spark Streaming API passes that batches to the core engine. Core engine can generate the final results in the form of streaming batches. The output also in the form of batches. It can allows streaming data and batch data for processing.
Q20) What is Spark MLlib?
Ans: Mahout is a machine learning library for Hadoop, similarly MLlib is a Spark library. MetLib provides different algorithms, that algorithms scale out on the cluster for data processing. Most of the data scientists use this MLlib library.
Q21) What is GraphX?
Ans: GraphX is a Spark API for manipulating Graphs and collections. It unifies ETL, other analysis, and iterative graph computation. It’s fastest graph system, provides fault tolerance and ease of use without special skills.
Q22) What is File System API?
Ans: FS API can read data from different storage devices like HDFS, S3 or local FileSystem. Spark uses FS API to read data from different storage engines.
Q23) Why Partitions are immutable?
Ans: Every transformation generates new partition. Partitions use HDFS API so that partition is immutable, distributed and fault tolerance. Partition also aware of data locality.
Q24) What is Transformation in spark?
Ans: Spark provides two special operations on RDDs called transformations and Actions. Transformation follows lazy operation and temporary hold the data until unless called the Action. Each transformation generates/return new RDD. Example of transformations: Map, flatMap, groupByKey, reduceByKey, filter, co-group, join, sortByKey, Union, distinct, sample are common spark transformations.
Q25) What is Action in Spark?
Ans: Actions are RDD’s operation, that value returns back to the spar driver programs, which kick off a job to execute on a cluster. Transformation’s output is an input of Actions. reduce, collect, takeSample, take, first, saveAsTextfile, saveAsSequenceFile, countByKey, foreach are common actions in Apache spark.
Q26) What is RDD Lineage?
Ans: Lineage is an RDD process to reconstruct lost partitions. Spark not replicate the data in memory, if data lost, Rdd use linege to rebuild lost data.Each RDD remembers how the RDD build from other datasets.
Q27) What is Map and flatMap in Spark?
Ans: The map is a specific line or row to process that data. In FlatMap each input item can be mapped to multiple output items (so the function should return a Seq rather than a single item). So most frequently used to return Array elements.
Q28) What are broadcast variables?
Ans: Broadcast variables let programmer keep a read-only variable cached on each machine, rather than shipping a copy of it with tasks. Spark supports 2 types of shared variables called broadcast variables (like Hadoop distributed cache) and accumulators (like Hadoop counters). Broadcast variables stored as Array Buffers, which sends read-only values to work nodes.
Q29) What are Accumulators in Spark?
Ans: Spark of-line debuggers called accumulators. Spark accumulators are similar to Hadoop counters, to count the number of events and what’s happening during job you can use accumulators. Only the driver program can read an accumulator value, not the tasks.
Q30) How RDD persist the data?
Ans: There are two methods to persist the data, such as persist() to persist permanently and cache() to persist temporarily in the memory. Different storage level options there such as MEMORY_ONLY, MEMORY_AND_DISK, DISK_ONLY and many more. Both persist() and cache() uses different options depends on the task.
Q31) When do you use apache spark? OR What are the benefits of Spark over Mapreduce?
Ans:
- Spark is really fast. As per their claims, it runs programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. It aptly utilizes RAM to produce the faster results.
- In map reduce paradigm, you write many Map-reduce tasks and then tie these tasks together using Oozie/shell script. This mechanism is very time consuming and the map-reduce task has heavy latency.
- And quite often, translating the output out of one MR job into the input of another MR job might require writing another code because Oozie may not suffice.
- In Spark, you can basically do everything using single application/console (pyspark or scala console) and get the results immediately. Switching between ‘Running something on cluster’ and ‘doing something locally’ is fairly easy and straightforward. This also leads to less context switch of the developer and more productivity.
- Spark kind of equals to MapReduce and Oozie put together.
Q32) Is there is a point of learning MapReduce, then?
Ans: Yes. For the following reason:
- MapReduce is a paradigm used by many big data tools including Spark. So, understanding the MapReduce paradigm and how to convert a problem into series of MR tasks is very important.
- When the data grows beyond what can fit into the memory on your cluster, the Hadoop Map-Reduce paradigm is still very relevant.
- Almost, every other tool such as Hive or Pig converts its query into MapReduce phases. If you understand the Mapreduce then you will be able to optimize your queries better.
Q33) When running Spark on Yarn, do I need to install Spark on all nodes of Yarn Cluster?
Ans: Since spark runs on top of Yarn, it utilizes yarn for the execution of its commands over the cluster’s nodes.
So, you just have to install Spark on one node.
Q34) What are the downsides of Spark?
Ans: Spark utilizes the memory. The developer has to be careful. A casual developer might make following mistakes:
- She may end up running everything on the local node instead of distributing work over to the cluster.
- She might hit some webservice too many times by the way of using multiple clusters.
The first problem is well tackled by Hadoop Map reduce paradigm as it ensures that the data your code is churning is fairly small a point of time thus you can make a mistake of trying to handle whole data on a single node.
The second mistake is possible in Map-Reduce too. While writing Map-Reduce, user may hit a service from inside of map() or reduce() too many times. This overloading of service is also possible while using Spark.
Q35) What is an RDD?
Ans: The full form of RDD is resilience distributed dataset. It is a representation of data located on a network which is
- Immutable – You can operate on the rdd to produce another rdd but you can’t alter it.
- Partitioned / Parallel – The data located on RDD is operated in parallel. Any operation on RDD is done using multiple nodes.
- Resilience – If one of the node hosting the partition fails, another nodes takes its data.
RDD provides two kinds of operations: Transformations and Actions.
Q36) What is Transformations?
Ans: The transformations are the functions that are applied on an RDD (resilient distributed data set). The transformation results in another RDD. A transformation is not executed until an action follows.
The example of transformations are:
- map() – applies the function passed to it on each element of RDD resulting in a new RDD.
- filter() – creates a new RDD by picking the elements from the current RDD which pass the function argument.
Q37) What are Actions?
Ans: An action brings back the data from the RDD to the local machine. Execution of an action results in all the previously created transformation. The example of actions are:
- reduce() – executes the function passed again and again until only one value is left. The function should take two argument and return one value.
- take() – take all the values back to the local node form RDD.
Q38) Say I have a huge list of numbers in RDD(say myrdd). And I wrote the following code to compute average:
Ans: def myAvg(x, y):
return (x+y)/2.0;
avg = myrdd.reduce(myAvg);
Q39) What is wrong with it? And How would you correct it?
Ans: The average function is not commutative and associative;
I would simply sum it and then divide by count.
1 2 3 4 | def sum(x, y):return x+y;total = myrdd.reduce(sum);avg = total / myrdd.count(); |
The only problem with the above code is that the total might become very big thus over flow. So, I would rather divide each number by count and then sum in the following way.
1 2 3 4 5 | cnt = myrdd.count();def devideByCnd(x):return x/cnt;myrdd1 = myrdd.map(devideByCnd);avg = myrdd.reduce(sum); |
Q40) Say I have a huge list of numbers in a file in HDFS. Each line has one number.And I want to compute the square root of sum of squares of these numbers. How would you do it?
Ans: # We would first load the file as RDD from HDFS on spark
numsAsText = sc.textFile(“hdfs://hadoop1.knowbigdata.com/user/student/sgiri/mynumbersfile.txt”);
# Define the function to compute the squaresdef toSqInt(str):
1 2 | v = int(str);return v*v; |
#Run the function on spark rdd as transformation
nums = numsAsText.map(toSqInt);
#Run the summation as reduce action
total = nums.reduce(sum)
#finally compute the square root. For which we need to import math.
1 2 | import math;print math.sqrt(total); |
Q41) Is the following approach correct? Is the sqrtOfSumOfSq a valid reducer?
Ans:
1 2 3 4 5 6 7 8 9 | numsAsText =sc.textFile(“hdfs://hadoop1.knowbigdata.com/user/student/sgiri/mynumbersfile.txt”);def toInt(str):return int(str);nums = numsAsText.map(toInt);def sqrtOfSumOfSq(x, y):return math.sqrt(x*x+y*y);total = nums.reduce(sum)import math;print math.sqrt(total); |
A: Yes. The approach is correct and sqrtOfSumOfSq is a valid reducer.
Q42) Could you compare the pros and cons of the your approach (in Question 2 above) and my approach (in Question 3 above)?
Ans: You are doing the square and square root as part of reduce action while I am squaring in map() and summing in reduce in my approach.
My approach will be faster because in your case the reducer code is heavy as it is calling math.sqrt() and reducer code is generally executed approximately n-1 times the spark RDD.
The only downside of my approach is that there is a huge chance of integer overflow because I am computing the sum of squares as part of map.
Q43) If you have to compute the total counts of each of the unique words on spark, how would you go about it?
Ans: #This will load the bigtextfile.txt as RDD in the spark lines =
sc.textFile(“hdfs://hadoop1.knowbigdata.com/user/student/sgiri/bigtextfile.txt”);
#define a function that can break each line into words
1 2 | def toWords(line):return line.split(); |
# Run the toWords function on each element of RDD on spark as flatMap transformation.
# We are going to flatMap instead of map because our function is returning multiple values.
words = lines.flatMap(toWords);
# Convert each word into (key, value) pair. Her key will be the word itself and value will be 1.
1 2 3 | def toTuple(word):return (word, 1);wordsTuple = words.map(toTuple); |
# Now we can easily do the reduceByKey() action.
1 2 3 | def sum(x, y):return x+y;counts = wordsTuple.reduceByKey(sum) |
# Now, print
counts.collect()
Q44) In a very huge text file, you want to just check if a particular keyword exists. How would you do this using Spark?
Ans:
1 2 3 4 5 6 7 8 9 10 11 | lines = sc.textFile(“hdfs://hadoop1.knowbigdata.com/user/student/sgiri/bigtextfile.txt”);def isFound(line):if line.find(“mykeyword”) > -1:return 1;return 0;foundBits = lines.map(isFound);sum = foundBits.reduce(sum);if sum > 0:print “FOUND”;else:print “NOT FOUND”; |
Q45) Can you improve the performance of this code in previous answer?
Ans: Yes. The search is not stopping even after the word we are looking for has been found. Our map code would keep executing on all the nodes which is very inefficient.
We could utilize accumulators to report whether the word has been found or not and then stop the job. Something on these line:
import thread, threading
from time import sleep
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | result = “Not Set”lock = threading.Lock()accum = sc.accumulator(0)def map_func(line):#introduce delay to emulate the slownesssleep(1);if line.find(“Adventures”) > -1:accum.add(1);return 1;return 0;def start_job():global resulttry:sc.setJobGroup(“job_to_cancel”, “some description”)lines = sc.textFile(“hdfs://hadoop1.knowbigdata.com/user/student/sgiri/wordcount/input/big.txt”);result = lines.map(map_func);result.take(1);except Exception as e:result = “Cancelled”lock.release()def stop_job():while accum.value < 3 :sleep(1);sc.cancelJobGroup(“job_to_cancel”)supress = lock.acquire()supress = thread.start_new_thread(start_job, tuple())supress = thread.start_new_thread(stop_job, tuple())supress = lock.acquire()[/tab] |
Facing technical problem in your current IT job, let us help you. MindMajix has highly technical people who can assist you in solving technical problems in your project.
We have come across many developers in USA, Australia and other countries who have recently got the job but they are struggling to survive in the job because of less technical knowledge, exposure and the kind of work given to them.
We are here to help you.
Let us know your profile and kind of help you are looking for and we shall do our best to help you out. The job support is provided by Mindmajix Technical experts who have more than 10 years of work experience on IT technologies landscape.

