Java Interview Questions for Experts
1.Explain a use case for the Builder Design Pattern?
Builder pattern aims to “Separate the construction of a complex object from its representation so that the same construction process can create different representations.” It is used to construct a complex object step by step and the final step will return the object. The process of constructing an object should be generic so that it can be used to create different representations of the same object.

- Product – The product class defines the type of the complex object that is to be generated by the builder pattern.
- Builder – This abstract base class defines all of the steps that must be taken in order to correctly create a product. Each step is generally abstract as the actual functionality of the builder is carried out in the concrete subclasses. The GetProduct method is used to return the final product. The builder class is often replaced with a simple interface.
- ConcreteBuilder – There may be any number of concrete builder classes inheriting from Builder. These classes contain the functionality to create a particular complex product.
- Director – The director class controls the algorithm that generates the final product object. A director object is instantiated and its Construct method is called. The method includes a parameter to capture the specific concrete builder object that is to be used to generate the product. The director then calls methods of the concrete builder in the correct order to generate the product object. On completion of the process, the GetProduct method of the builder object can be used to return the product.
Lets see an Example of Builder Design Pattern :
Consider a construction of a home. Home is the final end product (object) that is to be returned as the output of the construction process. It will have many steps like basement construction, wall construction and so on roof construction. Finally the whole home object is returned. Here using the same process you can build houses with different properties.
interface HousePlan { public void setBasement(String basement); public void setStructure(String structure); public void setRoof(String roof); public void setInterior(String interior); } class House implements HousePlan { private String basement; private String structure; private String roof; private String interior; public void setBasement(String basement) { this.basement = basement; } public void setStructure(String structure) { this.structure = structure; } public void setRoof(String roof) { this.roof = roof; } public void setInterior(String interior) { this.interior = interior; } } interface HouseBuilder { public void buildBasement(); public void buildStructure(); public void bulidRoof(); public void buildInterior(); public House getHouse(); } class IglooHouseBuilder implements HouseBuilder { private House house; public IglooHouseBuilder() { this.house = new House(); } public void buildBasement() { house.setBasement("Ice Bars"); } public void buildStructure() { house.setStructure("Ice Blocks"); } public void buildInterior() { house.setInterior("Ice Carvings"); } public void bulidRoof() { house.setRoof("Ice Dome"); } public House getHouse() { return this.house; } } class TipiHouseBuilder implements HouseBuilder { private House house; public TipiHouseBuilder() { this.house = new House(); } public void buildBasement() { house.setBasement("Wooden Poles"); } public void buildStructure() { house.setStructure("Wood and Ice"); } public void buildInterior() { house.setInterior("Fire Wood"); } public void bulidRoof() { house.setRoof("Wood, caribou and seal skins"); } public House getHouse() { return this.house; } } class CivilEngineer { private HouseBuilder houseBuilder; public CivilEngineer(HouseBuilder houseBuilder) { this.houseBuilder = houseBuilder; } public House getHouse() { return this.houseBuilder.getHouse(); } public void constructHouse() { this.houseBuilder.buildBasement(); this.houseBuilder.buildStructure(); this.houseBuilder.bulidRoof(); this.houseBuilder.buildInterior(); } } class Builder { public static void main(String[] args) { HouseBuilder iglooBuilder = new IglooHouseBuilder(); CivilEngineer engineer = new CivilEngineer(iglooBuilder); engineer.constructHouse(); House house = engineer.getHouse(); System.out.println("Builder constructed: "+ house); } } |
Output :
Builder constructed: House@6d06d69c
Advantages of Builder Design Pattern
- The parameters to the constructor are reduced and are provided in highly readable method calls.
- Builder design pattern also helps in minimizing the number of parameters in constructor and thus there is no need to pass in null for optional parameters to the constructor.
- Object is always instantiated in a complete state
- Immutable objects can be build without much complex logic in object building process.
Disadvantages of Builder Design Pattern
- The number of lines of code increase at least to double in builder pattern, but the effort pays off in terms of design flexibility and much more readable code.
- Requires creating a separate ConcreteBuilder for each different type of Product.
2.Is null check needed before calling instanceof?
No, a null check is not needed before using instanceof. … “At run time, the result of the instanceof operator is true if the value of the RelationalExpression is not null and the reference could be cast to the ReferenceType without raising a ClassCastException . Otherwise the result is false
3.What is Microservices and pros and cons of Microservice Architecture?
Microservices follow the principles of service-oriented architecture (SOA) design. Although SOA has no official standards, principles defined in Thomas Erl’s book entitled “SOA: Principles of Service Design” are often used as rules of thumb.
They are as follows:
- Standardized service contract (services follow a standardized description)
- Loose coupling (minimal dependencies)
- Service abstraction (services hide their internal logic)
- Service reusability (service structure is planned according to the DRY principle)
- Service autonomy (services internally control their own logic)
- Service statelessness (services don’t persist state from former requests)
- Service discoverability (services come with discoverable metadata and/or a service registry)
- Service composability (services can be used together)
Although SOA and microservices follow similar principles, their relationship is often debated. Some developers emphasize their similarity and consider microservices as a subtype of SOA. Others rather stress their differences and claim that each solves a different set of problems.
According to the latter view, SOA has an enterprise scope while microservices have an application scope. Within the enterprise scope, apps communicate with each other.
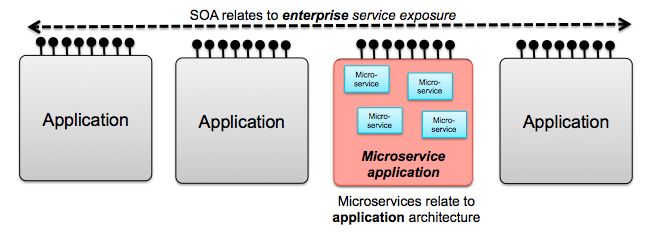
You can read more about the SOA vs microservices debate in this article by IBM DeveloperWorks. The most interesting question, however, is how microservices compare to monolithic applications.
So, let’s have a closer look at their pros and cons.
Pros of microservices
Microservices have become hugely popular in recent years. Mainly, because they come with a couple of benefits that are super useful in the era of containerization and cloud computing. You can develop and deploy each microservice on a different platform, using different programming languages and developer tools. Microservices use APIs and communication protocols to interact with each other, but they don’t rely on each other otherwise.
The biggest pro of microservices architecture is that teams can develop, maintain, and deploy each microservice independently. This kind of single-responsibility leads to other benefits as well. Applications composed of microservices scale better, as you can scale them separately, whenever it’s necessary. Microservices also reduce the time to market and speed up your CI/CD pipeline. This means more agility, too. Besides, isolated services have a better failure tolerance. It’s easier to maintain and debug a lightweight microservice than a complex application, after all.
Cons of microservices
As microservices heavily rely on messaging, they can face certain problems. Communication can be hard without using automation and advanced methodologies such as Agile. You need to introduce DevOps tools such as CI/CD servers, configuration management platforms, and APM tools to manage the network. This is great for companies who already use these methods. However, the adoption of these extra requirements can be a challenge for smaller companies.
Having to maintain a network lead to other kinds of issues, too. What we gain on the simplicity of single-responsibility microservices, lose on the complexity of the network. Or, at least a part of it. For instance, while independent microservices have better fault tolerance than monolithic applications, the network has worse.
Communication between microservices can mean poorer performance, as sending messages back and forth comes with a certain overhead. And, while teams can choose which programming language and platform they want to use, they also need to collaborate much better. After all, they need to manage the whole lifecycle of the microservice, from start to end.
To recap the main points, here are the pros and cons of microservices compared to monolithic applications:
| Pros | Cons | |||
|---|---|---|---|---|
| Greater agility | Needs more collaboration (each team has to cover the whole microservice lifecycle) | |||
| Faster time to market | Harder to test and monitor because of the complexity of the architecture | |||
| Better scalability | Poorer performance, as microservices need to communicate (network latency, message processing, etc.) | |||
| Faster development cycles (easier deployment and debugging) | Harder to maintain the network (has less fault tolerance, needs more load balancing, etc.) | |||
| Easier to create a CI/CD pipeline for single-responsibility services | Doesn’t work without the proper corporate culture (DevOps culture, automation practices, etc.) | |||
| Isolated services have better fault tolerance | Security issues (harder to maintain transaction safety, distributed communication goes wrong more likely, etc.) | |||
| Platform- and language agnostic services | ||||
| Cloud-readiness | ||||
Examples of Microservices
Microservices in Java
Java is one of the best languages to develop microservices. There are a couple of microservice frameworks for the Java platform you can use, such as:
- Dropwizard
- JHipster
- Spark framework
- Spring framework
- Swagger
- Play framework
- Vert.x
Using Spring Boot is the most popular way to build microservices in Java. Spring Boot is a utility built on top of the Spring platform. It makes it possible to set up stand-alone Spring apps with minimal configuration. It can save a lot of time by automatically configuring Spring and third-party libraries.
For instance, here’s a very simple microservices example by Paul Chapman, published in detail in the official Spring blog. It uses Spring, Spring Boot, and Spring Cloud to build the application. I won’t include code examples here, as you can find them in the original article. We’ll only briefly take a look at the application structure. The steps are as follows:
- Create the service registration (so that microservices can find each other), using the Eureka registration server (incorporated in Spring Cloud)
- Create an account management microservice called “Account Service” with Spring Boot
- Create a web service to access the microservice, using Spring’s
RestTemplateclass
Here’s an illustration of the app’s structure (also from the Spring blog):
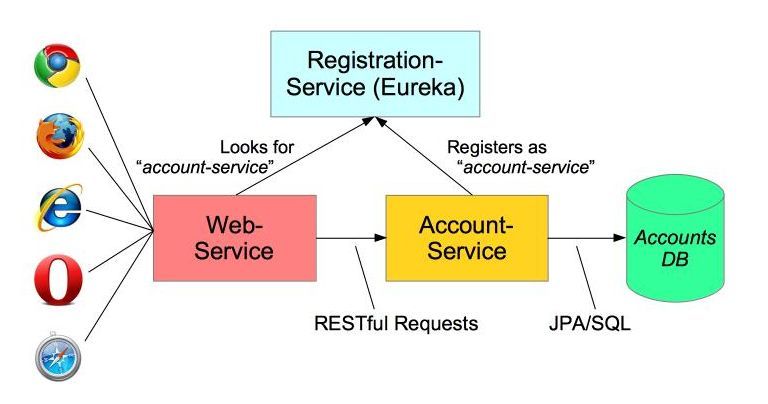
Of course, this is a very simple example. In real-life apps, the web service makes requests to more than one microservices.
4.What is Coupling in OOP?
In object oriented design, Coupling refers to the degree of direct knowledge that one element has of another. In other words, how often do changes in class A force related changes in class B. There are two types of coupling: Tight coupling : In general, Tight coupling means the two classes often change together.
5.What is Double Brace initialization in Java?
Double brace initialization is a combination of two separate process in java. … When you use the initialization block for an anonymous inner class it becomes java double brace initialization. The inner class created will have a reference to the enclosing outer class. That reference can be used using the ‘this’ pointer
6.What is Materialized View pattern and when will you use it?
Materialized View Pattern
Context and Problem
When storing data, the priority for developers and data administrators is often focused on how the data is stored, as opposed to how it is read. The chosen storage format is usually closely related to the format of the data, requirements for managing data size and data integrity, and the kind of store in use.
For example, when using NoSQL Document store, the data is often represented as a series of aggregates, each of which contains all of the information for that entity.
However, this may have a negative effect on queries. When a query requires only a subset of the data from some entities, such as a summary of orders for several customers without all of the order details, it must extract all of the data for the relevant entities in order to obtain the required information.
Solution
To support efficient querying, a common solution is to generate, in advance, a view that materializes the data in a format most suited to the required results set. The Materialized View pattern describes generating prepopulated views of data in environments where the source data is not in a format that is suitable for querying, where generating a suitable query is difficult, or where query performance is poor due to the nature of the data or the data store.
These materialized views, which contain only data required by a query, allow applications to quickly obtain the information they need. In addition to joining tables or combining data entities, materialized views may include the current values of calculated columns or data items, the results of combining values or executing transformations on the data items, and values specified as part of the query. A materialized view may even be optimized for just a single query.
A key point is that a materialized view and the data it contains is completely disposable because it can be entirely rebuilt from the source data stores. A materialized view is never updated directly by an application, and so it is effectively a specialized cache.
When the source data for the view changes, the view must be updated to include the new information. This may occur automatically on an appropriate schedule, or when the system detects a change to the original data. In other cases it may be necessary to regenerate the view manually.
Below shows an example of how the Materialized View pattern might be used.

The Materialized View pattern
When to Use this Pattern
This pattern is ideally suited for:
- Creating materialized views over data that is difficult to query directly, or where queries must be very complex in order to extract data that is stored in a normalized, semi-structured, or unstructured way.
- Creating temporary views that can dramatically improve query performance, or can act directly as source views or data transfer objects (DTOs) for the UI, for reporting, or for display.
- Supporting occasionally connected or disconnected scenarios where connection to the data store is not always available. The view may be cached locally in this case.
- Simplifying queries and exposing data for experimentation in a way that does not require knowledge of the source data format. For example, by joining different tables in one or more databases, or one or more domains in NoSQL stores, and then formatting the data to suit its eventual use.
- Providing access to specific subsets of the source data that, for security or privacy reasons, should not be generally accessible, open to modification, or fully exposed to users.
- Bridging the disjoint when using different data stores based on their individual capabilities. For example, by using a cloud store that is efficient for writing as the reference data store, and a relational database that offers good query and read performance to hold the materialized views.
This pattern might not be suitable in the following situations:
- The source data is simple and easy to query.
- The source data changes very quickly, or can be accessed without using a view. The processing overhead of creating views may be avoidable in these cases.
- Consistency is a high priority. The views may not always be fully consistent with the original data.
7.Why is char[] preferred over String for passwords?
Since Strings are immutable there is no way the contents of Strings can be changed because any change will produce a new String, while if you use a char[] you can still set all the elements as blank or zero. So storing a password in a character array clearly mitigates the security risk of stealing a password
8.Compare volatile vs static variables in Java?
Declaring a static variable in Java, means that there will be only one copy, no matter how many objects of the class are created. The variable will be accessible even with no Objects created at all. However, threads may have locally cached values of it.
When a variable is volatile and not static, there will be one variable for each Object. So, on the surface it seems there is no difference from a normal variable but totally different from static. However, even with Object fields, a thread may cache a variable value locally.
This means that if two threads update a variable of the same Object concurrently, and the variable is not declared volatile, there could be a case in which one of the thread has in cache an old value.
Even if you access a static value through multiple threads, each thread can have its local cached copy! To avoid this you can declare the variable as static volatile and this will force the thread to read each time the global value.
However, volatile is not a substitute for proper synchronisation!
For instance:
private static volatile int counter = 0;private void concurrentMethodWrong() { counter = counter + 5; //do something counter = counter - 5;}Executing concurrentMethodWrong concurrently many times may lead to a final value of counter different from zero!
To solve the problem, you have to implement a lock:
private static final Object counterLock = new Object();private static volatile int counter = 0;private void concurrentMethodRight() { synchronized (counterLock) { counter = counter + 5; } //do something synchronized (counterLock) { counter = counter - 5; }}Or use the AtomicInteger class.
9.What is an efficient way to implement a singleton pattern in Java?
public enum Foo { INSTANCE;} Joshua Bloch explained this approach in his Effective Java Reloaded talk at Google I/O 2008: link to video. Also see slides 30-32 of his presentation (effective_java_reloaded.pdf):The Right Way to Implement a Serializable Singleton
public enum Elvis { INSTANCE; private final String[] favoriteSongs = { "Hound Dog", "Heartbreak Hotel" }; public void printFavorites() { System.out.println(Arrays.toString(favoriteSongs)); }} "This approach is functionally equivalent to the public field approach, except that it is more concise, provides the serialization machinery for free, and provides an ironclad guarantee against multiple instantiation, even in the face of sophisticated serialization or reflection attacks. While this approach has yet to be widely adopted, a single-element enum type is the best way to implement a singleton."10.What’s the difference between SoftReference and WeakReference in Java?
Weak references
A weak reference, simply put, is a reference that isn’t strong enough to force an object to remain in memory. Weak references allow you to leverage the garbage collector’s ability to determine reachability for you, so you don’t have to do it yourself. You create a weak reference like this:
WeakReference weakWidget = new WeakReference(widget);and then elsewhere in the code you can use weakWidget.get() to get the actual Widget object. Of course the weak reference isn’t strong enough to prevent garbage collection, so you may find (if there are no strong references to the widget) that weakWidget.get() suddenly starts returning null.
Soft references
A soft reference is exactly like a weak reference, except that it is less eager to throw away the object to which it refers. An object which is only weakly reachable (the strongest references to it are WeakReferences) will be discarded at the next garbage collection cycle, but an object which is softly reachable will generally stick around for a while.
SoftReferences aren’t required to behave any differently than WeakReferences, but in practice softly reachable objects are generally retained as long as memory is in plentiful supply. This makes them an excellent foundation for a cache, such as the image cache described above, since you can let the garbage collector worry about both how reachable the objects are (a strongly reachable object will never be removed from the cache) and how badly it needs the memory they are consuming.
